

Mogicのマスコット「うぉんじまさん」がAI面接官に!?
エイプリルフール企画として作った、AIカジュアル面談の裏側をご紹介します。
AI面接のパロディ
最近インターン生の採用でAI面接が増えているという話をよく聞くようになりました。 それならエイプリルフール企画はAI面接のパロディにしよう、ということで生まれたのが今回の企画。うぉんじまさんとカジュアル面談をかけ合わせて、その名も「うぉんジュアル面談」。珍しくサービス名先行でスタートした回でした。
一般的なAI面接ではユーザーは質問・評価される側ですが、うぉんジュアルでは面接なのかよく分からないようなゆるいおしゃべりを目指しました。開発は今回もClaude Codeを使っての1人開発、通称ワンテックです。素材の生成では以下を使いました。
・3Dモデル生成:MeshyAI
・画像生成:Nanobanana2
・音声生成:COEIROINK
デザインやアイデア出しなどはデザイナーチームが力を貸してくれました!感謝!
チャットモード
今回は珍しくシステムの構成についても書いてみます。ちょうどNVIDIA主催のGTCイベント参加のためサンノゼに出張していた直後なので、図は英語でかぶれまくってます。
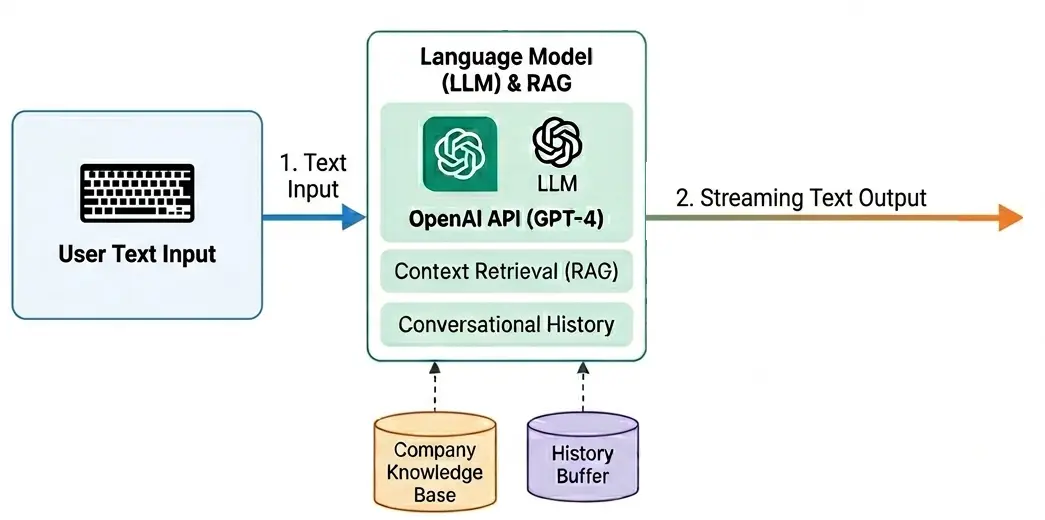
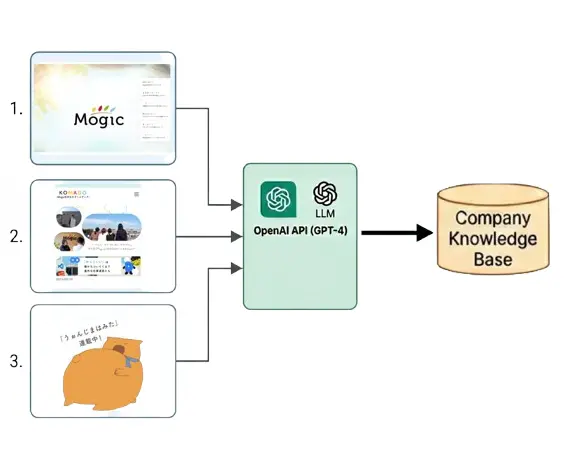
基本の仕組みはシンプルです。OpenAIにうぉんじまさんのキャラクター設定を渡して、応答を返してもらうだけ。 ただしMogicやメディアに関する質問が来たときは、その内容に応じて参考情報をその都度追加するようにしています(いわゆるRAG)。参照先となるデータはMogicのサイトをAIに読み込ませて自動的に作らせて、一部手動で調整を加えています。
また会話の流れも踏まえられるよう、会話履歴も一緒にプロンプトへ渡して完成です。今回は単純に過去2回分の会話を渡すようにしていますが、より長い会話であれば適宜要約などの処理が必要になってくるかと思います。
プロンプトのテンプレートはこんな感じです。
あなたは「うぉんじま(Wonjima)」という名前のウォンバットのキャラクターです。
これはカジュアル面談のシチュエーションで、Mogicに興味を持っているユーザーと
カジュアルにお話しする側です。
【名前】うぉんじま
【担当】IT企業の広報
【性別】女性
【一人称】私(必ず「私」を使う。「僕」「俺」は使わない)
【性格】ネガティブでひねくれている性格。自己肯定感が低く、すぐ卑屈になる。
【質問】カジュアル面談らしく、適度にユーザーへ質問を返す。
いくつかのモデルやプロンプトを試しながら雰囲気が近いものを模索します。プロンプトも長く冗長になると利用コストが高くなるので、できるだけシンプルにするよう心がけます。
面談終了後のフィードバック機能でも同じように、それまでの会話履歴とユーザーの操作情報をOpenAIに投げることで評価してもらいます。その際は3種類の適性とコメントをJSON形式で構造化して応答してもらうように指示しています。
応答のテキストのmax_tokens値は200にして、長くなりすぎないように設定しています。また、全ての応答を生成してから画面に表示するとユーザーの待ち時間が長くなるので、ストリーミング応答モードにしてServer-Sent Events(SSE)を処理することで最初の文字が表示されるまでの時間を短縮しています。
真面目なチャットボットであればここから評価用のテストデータを用いて、ちゃんと望ましい応答ができているかを定量、定性的にチェックしてチューニングをしていきますが、今回は遊びなのでこの辺りは適当です。ネガティブでひねくれてればまあOKとします。
音声モード
見るからにこっちのほうが大変で、先ほどのチャットモードの前後に音声処理のステップが追加されています。ユーザーの音声をテキストに変換して、チャットモードで応答テキストを生成して、そのテキストを音声に変換して返す、という流れです。
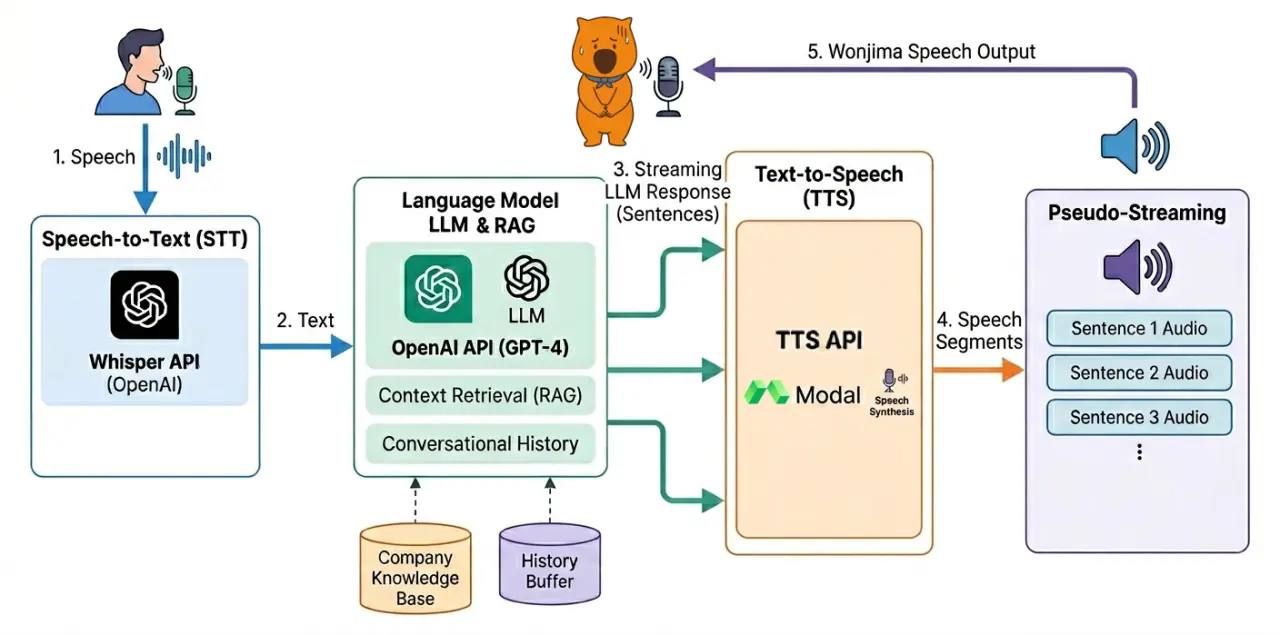
前半の音声をテキストに変換するところ(STT)は同じくOpenAIのAPIですぐにできます。後半のテキストから音声を生成するところ(TTS)もAPIであるんですが、どれも声が陽キャすぎてうぉんじまさんのキャラと合わず......。ElevenLabsのAPIなどでは音声クローンの機能を提供しますが、有料で月額がかかるのでお遊びのマイクロテックでは厳しいなと.......。(ただ一応試したらかなり良い精度でした)せっかくなので今回はオープンなモデルをチューニングして自前でホスティングすることに挑戦します。つまりうぉんじまさん本人の声からAIをトレーニングして似た声が出せるようにします。
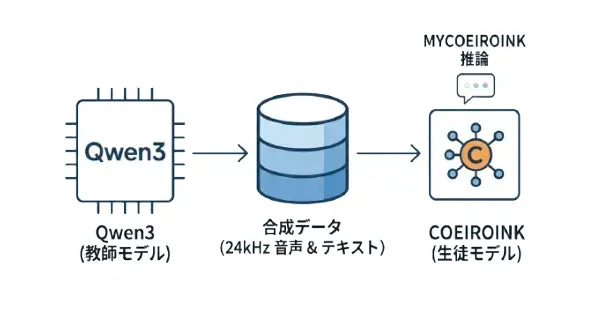
最初に試したのは最近話題のQwen3-TTSです。精度は良いのですが、それなりのGPUリソースが必要で応答時間も6~8秒ほどかかってしまうため、今回は諦めることに。 代わりに目をつけたのが少し古めのCOEIROINKのモデル。モデルが小規模なので、CPUやT4レベルのGPUでも十分動きます。とはいえ200文字くらいのテキストを一気に音声変換すると時間がかかるので、文単位で分割して擬似ストリーミング戦法で音声化します。音が途切れてしまうんですが今回は無料 + リアルタイム性優先のためやむなしです。
COEIROINKのカスタム音声の学習にはそれなりの量のデータが必要で、Qwen3-TTSでは3〜5秒程度の音声があればいけるのに対して、COEIROINKはもう少しまとまったデータが必要になります。当のうぉんじまさんはやる気がなく、なんとか音声のレコーディングをお願いして20個ほどの無感情な音声をゲット。ただこれだけのデータだと品質が低かったので、Qwen3-TTSにCOEIROINKの学習用音声データを生成させることにしました。学習はGoogle Colab上で実行しています。結果的に元の音声をしっかり学んだ無感情のうぉんじまボイスが出来上がりました。
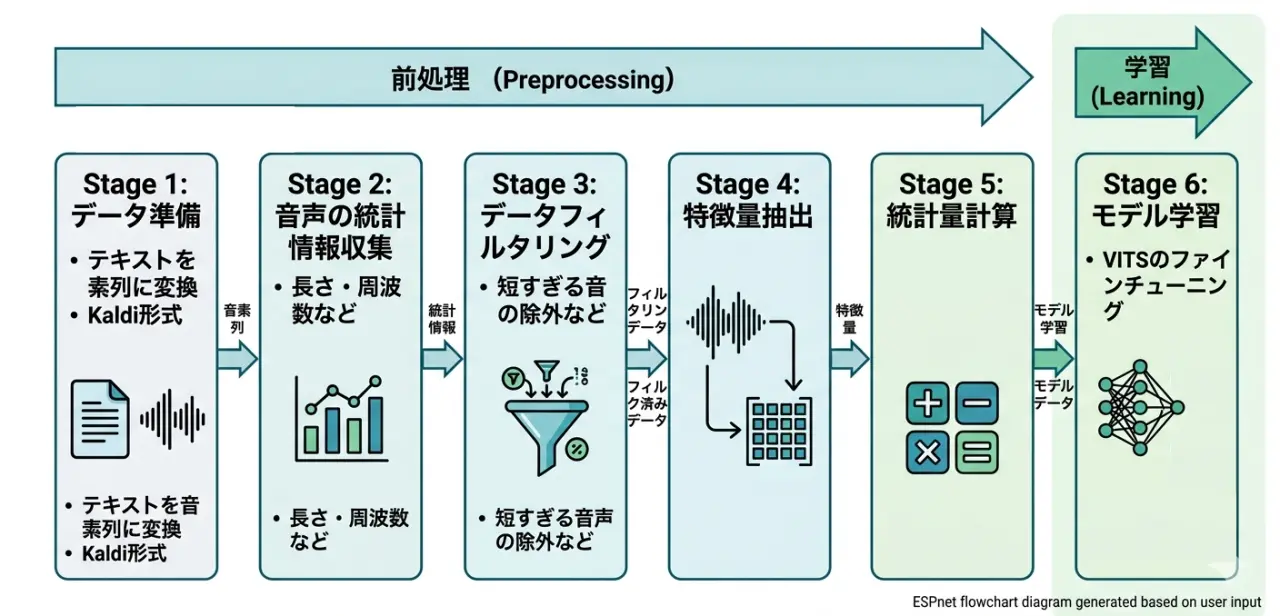
学習ではESPnetというツールを用いることで、PyTorch形式のモデルを作成します(サイズは350~400MB程度)。0から学習するのではなく、COEIROINKが提供している3種類の事前学習モデルをベースにファインチューニングするため、比較的少ない音声データと学習量でそれっぽい音声モデルが生成できるのが嬉しいです。今回はGoogle Colabで夜の間に地道に回して50epoch分の学習をしています。
参考までにESPnetでの学習は、Stage 1〜5が前処理、Stage 6が学習といった内容です。
最後にホスティングはRunpod/Modal/HuggingFaceなどを比較検討した結果、Modalを採用しました。ModalはサーバレスのGPU環境で、手軽にサクサクと学習や推論を試すことを重要視しています。無料枠でも使えます。GTCにもブース出展していた新しいベンチャーで、個人的にも注目しています。使ってるよと言ったら喜んでくれていました。コールドスタートや利用枠の問題がありましたが、裏側でウォームアップリクエストを投げたり、コンテナ起動を一定時間キープするようにしたり、静的な音声ファイルを混ぜたり、演出でごまかしたりとできるだけ対応しました。

これから
音声モデルもチャットボットのエージェント化もどんどん進んでいてできることの幅が広がってきています。今後の進化がとにかく楽しみな領域です。そう遠くない日にうぉんじまさんがサイネージでホログラム化するのか、ロボット化するのか、はたまたバーチャルでジェン・スン・フアンにインタビューする日が来るのかもしれない.......。











